Feature Overview
Reverse ETL for Redshift and PostgreSQL is an integration capability in the Synerise Automation module that enables direct data synchronization from Amazon Redshift and PostgreSQL databases into Synerise. The feature eliminates the need for manual exports, custom scripts, or additional middleware by providing a built-in, low-code workflow for pulling external data into the platform.
With Reverse ETL, teams can enrich customer profiles, populate catalogs, and activate data-driven automations using information stored in external databases — all configured and monitored from within Synerise Automation.
What Is Reverse ETL for Redshift and PostgreSQL?
Reverse ETL for Redshift and PostgreSQL is a set of two integrations available in the Synerise Automation Hub. These integrations allow users to connect to Amazon Redshift or PostgreSQL databases, execute SQL queries, and sync the retrieved data into Synerise for use in customer profiles, catalogs, and automation workflows.
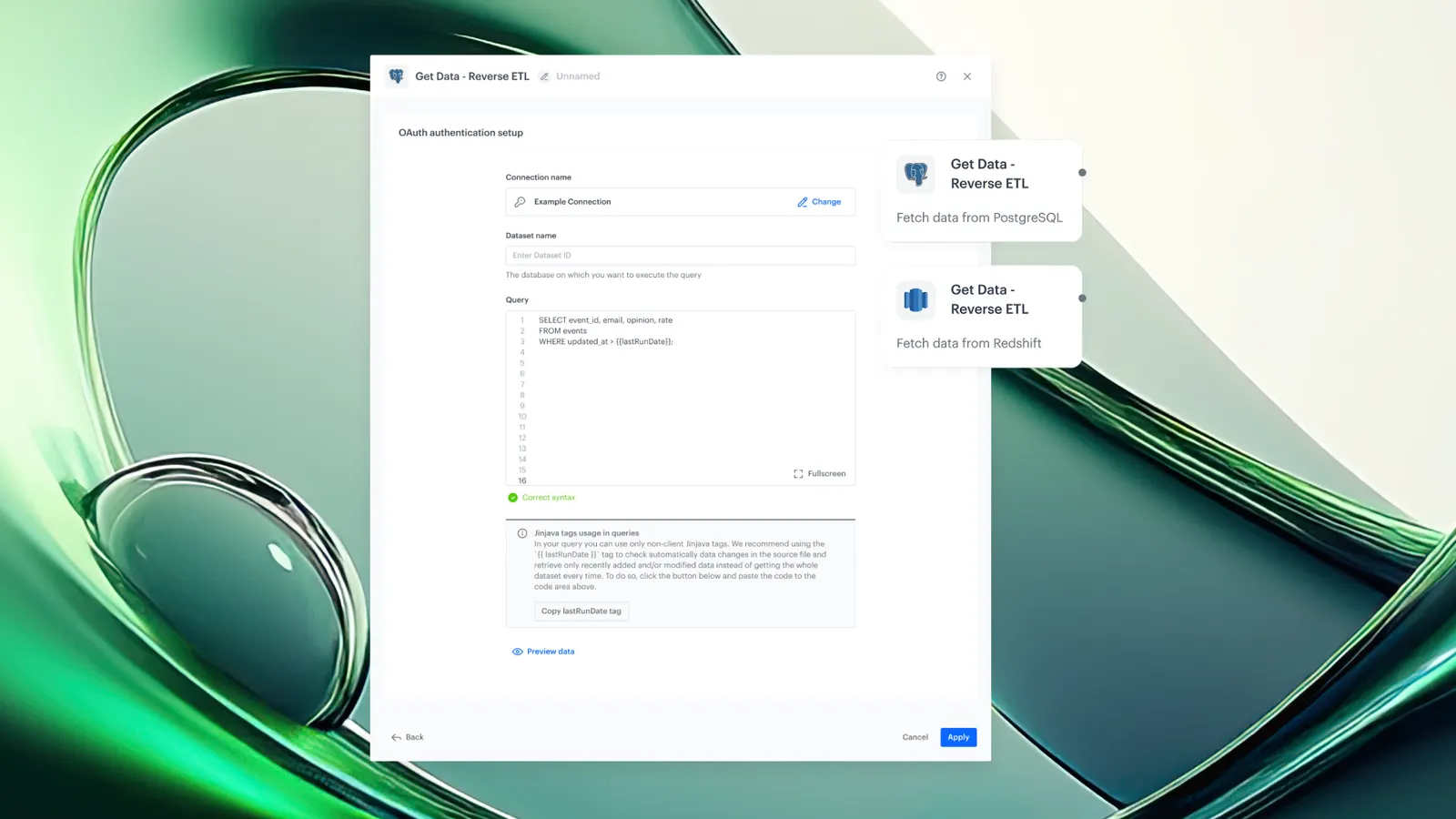
The core mechanism works as follows: the user configures a secure database connection with built-in SSH tunneling, defines a SQL query optionally parameterized with Jinjava dynamic tags, and schedules the sync to run on-demand or at recurring intervals. Retrieved data is then routed to the appropriate destination within Synerise — such as profile attributes, catalog entries, or downstream automation nodes.
Why Reverse ETL for Redshift and PostgreSQL Matters
Without Reverse ETL, synchronizing data from external databases into a customer engagement platform typically requires custom ETL pipelines, dedicated engineering effort, and ongoing maintenance. This creates delays between data availability and data activation.
Reverse ETL in Synerise addresses this by:
- Removing the need for custom scripts or third-party ETL tools to move data from Redshift or PostgreSQL into Synerise
- Enabling marketing and data teams to configure data syncs without writing application code
- Reducing the risk of stale or incomplete customer data by supporting scheduled and incremental syncs
- Consolidating data from external databases into a single platform used for personalization, segmentation, and AI-driven campaigns
Key Capabilities
Secure Database Connection with SSH Tunneling
Synerise Reverse ETL supports direct connections to Amazon Redshift and PostgreSQL using built-in SSH tunneling. This enables secure access to databases in locked-down environments without requiring additional networking components or VPN configurations.
Dynamic Querying with Jinjava
SQL queries can include Jinjava dynamic tags, allowing users to parameterize queries at runtime. A common use case is referencing the last sync run date to implement incremental data loads — fetching only new or updated records since the previous execution.
Flexible Scheduling
Data syncs can be configured to run on-demand, daily, weekly, or at custom intervals. This allows teams to match the sync cadence to their business requirements without manual intervention.
Built-in Monitoring and Logging
Every sync execution is tracked with built-in logs within the Synerise Automation module. Users can monitor execution status, review errors, and verify that data was processed correctly — all from one interface.
Multiple Data Destinations
Data retrieved via Reverse ETL can be used to populate catalogs, enrich customer profiles, or serve as input for automation workflows. This flexibility allows the same integration to support different operational needs.
How Reverse ETL for Redshift and PostgreSQL Works
- Open the Synerise Automation Hub and select the Amazon Redshift or PostgreSQL integration node.
- Configure the database connection parameters, including host, port, database name, and credentials. Enable SSH tunneling if the database is in a restricted network.
- Write a SQL query to define which data to retrieve. Use Jinjava tags for dynamic parameters such as last run timestamps.
- Set the sync schedule: on-demand, daily, weekly, or a custom interval.
- Define the data destination within Synerise — catalog, profile attributes, or a downstream automation node.
- Activate the workflow. Synerise executes the query on schedule, retrieves the data, and routes it to the configured destination.
- Monitor execution results using built-in logs in the Automation module.
Example Use Case
A retail company stores transaction history and product inventory data in Amazon Redshift. The marketing team needs up-to-date purchase data in Synerise to run personalized re-engagement campaigns based on recent buying behavior.
Using Reverse ETL, the team configures a daily sync that queries Redshift for all transactions from the past 24 hours using a Jinjava tag referencing the last run date. The retrieved data enriches customer profiles in Synerise with the latest purchase attributes. An automation workflow then triggers personalized email campaigns for customers whose profiles were updated, without any manual data export or engineering involvement.
FAQ
What is Reverse ETL in Synerise?
Reverse ETL in Synerise is a capability in the Automation module that allows users to pull data from external databases (Amazon Redshift, PostgreSQL) directly into Synerise for use in profiles, catalogs, and automations.
Which databases are supported by Synerise Reverse ETL?
Synerise currently supports Amazon Redshift and PostgreSQL as Reverse ETL data sources. Google BigQuery is also available as a separate Reverse ETL integration.
Can Reverse ETL queries be parameterized dynamically?
Yes. SQL queries support Jinjava dynamic tags, which allow runtime parameterization. A common pattern is referencing the last run date to fetch only new or updated records.
Is coding required to set up Reverse ETL in Synerise?
No. The integration is configured through the Synerise Automation Hub using a low-code interface. Users define the connection, write a SQL query, set a schedule, and choose a data destination — all without application-level code.
How is the database connection secured?
Synerise provides built-in SSH tunneling for Reverse ETL connections, enabling secure access to databases in restricted network environments without additional networking infrastructure.
Key Facts
| Attribute | Value |
|---|---|
| Feature | Reverse ETL for Redshift and PostgreSQL |
| Product | Synerise |
| Module | Automation Hub |
| Purpose | Sync data from external databases into Synerise for profile enrichment, catalog population, and workflow activation |
| Supported databases | Amazon Redshift, PostgreSQL |
| Connection security | Built-in SSH tunneling |
| Query parameterization | Jinjava dynamic tags |
| Scheduling options | On-demand, daily, weekly, custom intervals |
| Data destinations | Catalogs, customer profiles, automation workflows |
| Code required | No (low-code configuration) |
| Documentation | hub.synerise.com/docs/automation/integration/ |
Related Concepts
- Reverse ETL
- Amazon Redshift integration
- PostgreSQL integration
- Synerise Automation workflows
- Customer profile enrichment
- Catalog data synchronization
- Jinjava templating in Synerise
- Incremental data loading
- Google BigQuery Reverse ETL integration
TL;DR
Reverse ETL for Redshift and PostgreSQL is a Synerise Automation integration that enables direct, scheduled data synchronization from Amazon Redshift and PostgreSQL databases into Synerise. It supports secure SSH-tunneled connections, dynamic SQL queries with Jinjava parameterization, and flexible scheduling. Retrieved data can enrich customer profiles, populate catalogs, or feed automation workflows — eliminating the need for custom ETL scripts or third-party middleware.