Feature Overview
Databricks Integration is a Reverse ETL connector in Synerise that enables pulling data directly from a Databricks environment and activating it within the Synerise platform. The integration allows data stored or processed in Databricks — including analytics outputs, AI model results, and customer data pipelines — to be used in Synerise for segmentation, campaigns, personalization, and reporting.
The feature is available as a Reverse ETL integration in the Synerise Automation module, alongside existing connectors for Snowflake and Google BigQuery.
What Is Databricks Integration?
Databricks Integration is a Reverse ETL connection in Synerise that retrieves data from Databricks and makes it available for activation within the Synerise platform. Once configured, data from Databricks tables and views can be pulled into Synerise and used for customer segmentation, campaign targeting, personalization, and reporting — without manual data exports or custom API development.
Why Databricks Integration Matters
Teams using Databricks for advanced analytics, AI model training, or data pipeline management often need to activate those results in their customer engagement platform. Without a native integration, this requires manual data exports, scheduled batch transfers, or custom ETL pipelines — creating delays and operational overhead.
Databricks Integration addresses this by:
- Pulling data directly from Databricks into Synerise for immediate activation — no manual export required
- Enabling segmentation, campaigns, personalization, and reporting based on Databricks data
- Joining an existing ecosystem of Reverse ETL connectors (Snowflake, Google BigQuery) for unified data activation
- Reducing friction for teams building data pipelines at scale
Key Capabilities
Reverse ETL data pull from Databricks
Data is pulled directly from Databricks tables and views into Synerise. This includes analytics outputs, AI model predictions, customer attributes, and any structured data available in the Databricks environment.
Data activation in Synerise
Once pulled into Synerise, Databricks data can be used for customer segmentation, campaign targeting, personalization logic, and reporting dashboards — without additional processing steps.
Part of the Reverse ETL ecosystem
Databricks Integration joins Snowflake and Google BigQuery as supported Reverse ETL connectors in Synerise, providing a consistent integration pattern for teams using multiple data platforms.
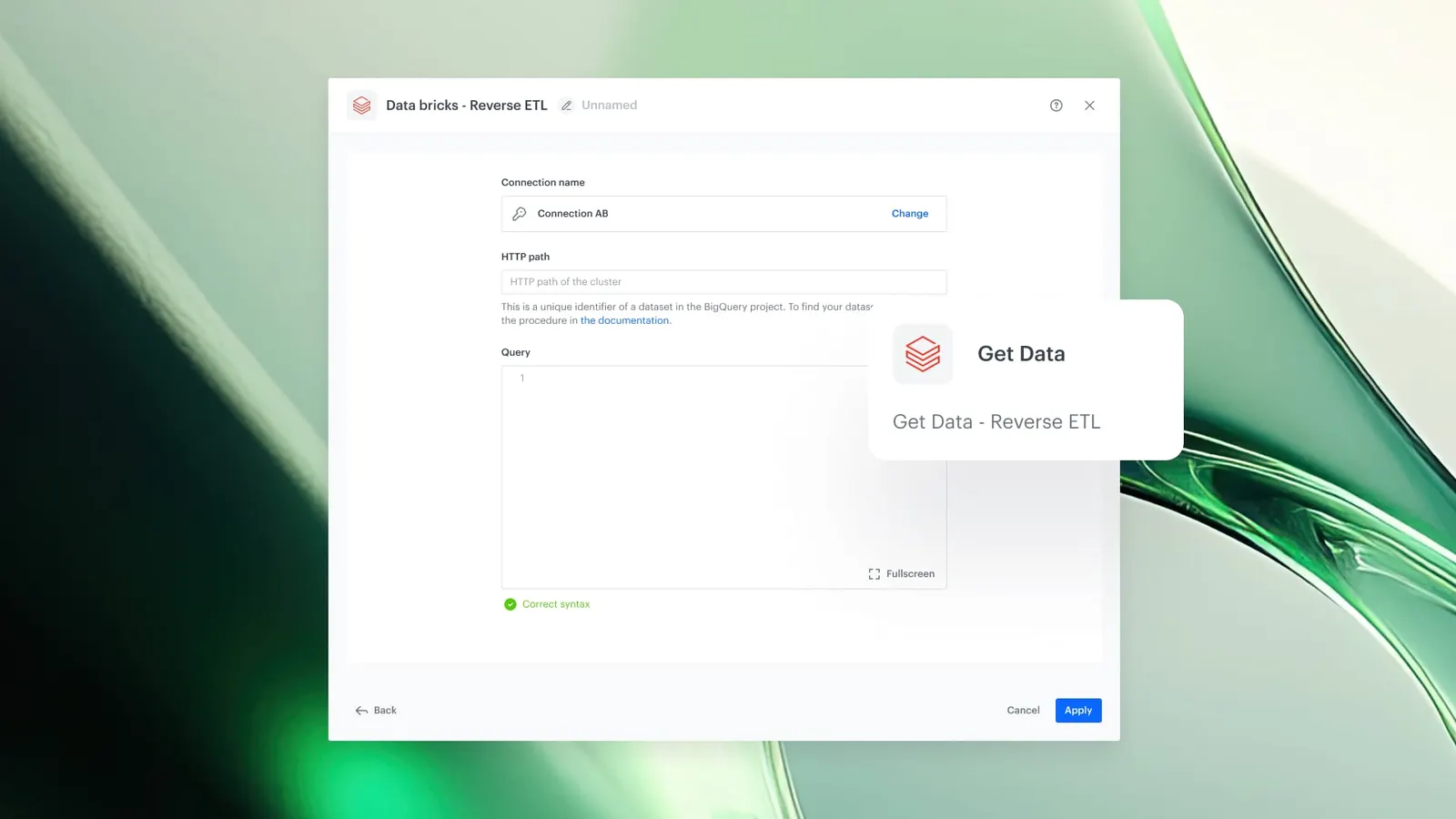
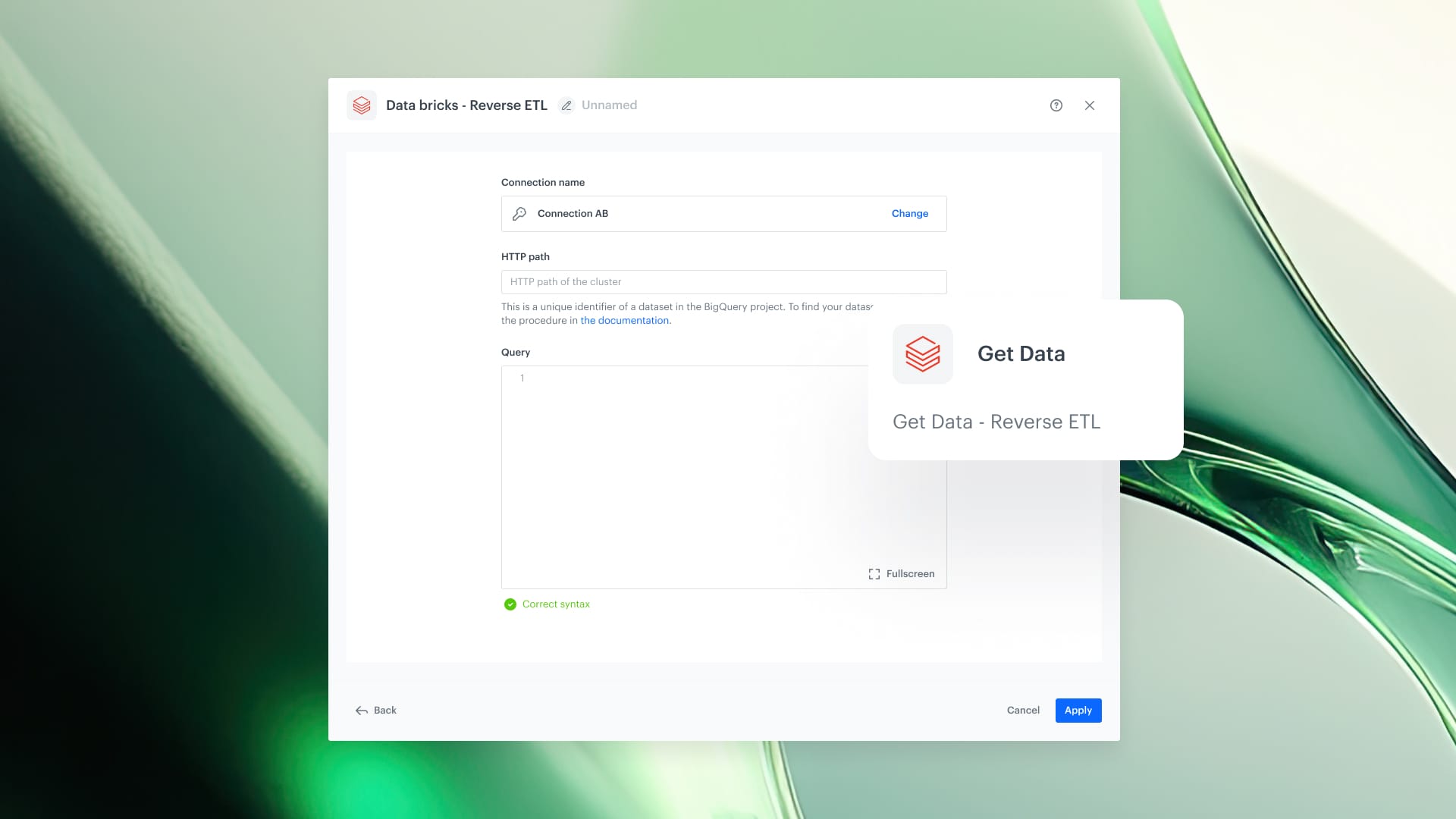
How Databricks Integration Works
- Navigate to Automation in Synerise and configure the Databricks Reverse ETL integration.
- Provide Databricks connection credentials and specify the data source (table or view).
- Configure the data mapping to define how Databricks data maps to Synerise attributes.
- Set the sync schedule or trigger the data pull manually.
- Use the activated data in Synerise for segmentation, campaigns, personalization, and reporting.
Example Use Case
A financial services company uses Databricks to run churn prediction models. The model outputs a churn risk score for each customer. Using the Databricks Reverse ETL integration, churn scores are pulled into Synerise and used to create a "high churn risk" segment. The marketing team targets this segment with a retention campaign — personalized offers via email and push notifications — all without manual data exports or custom pipeline development.
FAQ
What is Databricks Integration in Synerise?
It is a Reverse ETL connector that pulls data from Databricks into Synerise for use in segmentation, campaigns, personalization, and reporting.
What types of data can be pulled from Databricks?
Any structured data available in Databricks tables or views — including analytics outputs, AI model predictions, and customer attributes.
What other Reverse ETL integrations does Synerise support?
Synerise also supports Reverse ETL integrations with Snowflake and Google BigQuery.
Is custom API development required?
No. The integration is configured within Synerise Automation — no custom code or API development is needed.
Key Facts
| Attribute | Value |
|---|---|
| Feature | Databricks Integration (Reverse ETL) |
| Product | Synerise |
| Module | Automation (Reverse ETL) |
| External platform | Databricks |
| Purpose | Pull data from Databricks and activate it in Synerise |
| Data activation | Segmentation, campaigns, personalization, reporting |
| Other connectors | Snowflake, Google BigQuery |
| Documentation | hub.synerise.com — Databricks Reverse ETL |
Related Concepts
- Reverse ETL in Synerise
- Data activation and segmentation
- Databricks data platform
- Synerise Automation integrations
- Customer data pipeline management
TL;DR
Databricks Integration is a Reverse ETL connector in Synerise that pulls data directly from Databricks for activation in segmentation, campaigns, personalization, and reporting. It joins existing Snowflake and Google BigQuery connectors, enabling teams to activate Databricks analytics, AI model outputs, and customer data within Synerise — without manual exports or custom API development.